
Retrieval-augmented generation, or RAG, is a technique for enhancing the output of large language models by incorporating information from external knowledge bases or sources.
By retrieving relevant data or documents before generating a response, RAG improves the generated text’s accuracy, reliability, and informativeness. This approach helps ground the generated content in external sources of information, ensuring that the output is more contextually relevant and factually accurate.
Read on to learn more about RAG, how it works, its use cases, and how it differs from the traditional process of natural language processing (NLP).
TABLE OF CONTENTS
What Exactly is Retrieval-Augmented Generation (RAG)?
You’ve probably heard people say that AI-generated content is susceptible to plagiarism and lack of originality. In traditional natural language processing tasks, language models generate responses based solely on patterns and information in their training data. While this approach has shown impressive results, it also comes with limitations, such as the potential for generating incorrect or biased output, especially when dealing with complex or ambiguous queries.
Retrieval-augmented generation is a technique that addresses this issue by combining the power of both natural language processing and information retrieval.
Imagine trying to write a research paper without access to the Internet or any external resources. You may have a general understanding of the topic, but to support your arguments and provide in-depth analysis, you need to consult various sources of information.
This is where RAG comes in — it acts as your research assistant, helping you access and integrate relevant information to enhance the quality and depth of your work.
Large language models (LLMs) are trained on vast volumes of data. They are like well-read individuals who have a broad understanding of various topics and subjects. They can provide general information and answer various queries based on their vast knowledge-base. But to generate more precise, reliable, and detailed responses backed up by specific evidence or examples, LLMs often need the assistance of RAG techniques. This is similar to how even the most knowledgeable person may need to consult references or sources to provide thorough and accurate responses in certain situations.
To gain a deeper understanding of today’s top large language models, read our guide to Best Large Language Models
How Retrieval-Augmented Generation Works in Practice
Retrieval-augmented generation (RAG) is a AI model architecture that combines the strengths of pre-trained parametric models (like transformer-based models) with non-parametric memory retrieval, enabling the generation of text conditioned on both the input prompt and external knowledge sources.
The workability of the RAG model starts from the user query or prompt. The retrieval model is activated when you type your questions into your generative AI text field.
Query Phase
In the query or prompt phase, the system searches a large knowledge source to find relevant information based on the input query or prompt. This knowledge source could be a collection of documents, a database, or any other structured or unstructured data repository. It could also be your company knowledge base.
For example, if the input query is “What are the symptoms of COVID-19?” the RAG system would search and retrieve relevant information from a database of medical documents or articles.
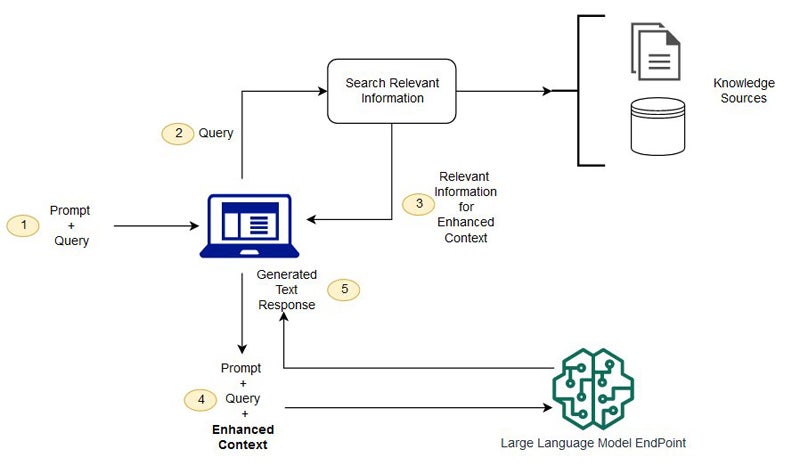
Retrieval
Once the relevant information is found, the RAG system selects a set of candidate passages or documents likely to contain useful information for generating a response. This step helps filter out irrelevant or redundant information and only picks the most relevant answer to your question.
In the COVID-19 example, the system might select passages from medical articles that list common symptoms associated with the disease.
Generation Phase
In the generation phase, the result is returned to the user. RAG uses the selected candidate passages as context to generate a response or text.
This generation process can be based on various techniques, such as neural language models (e.g., GPT) or other generation architectures. The generated response should be coherent, relevant, and informative based on the input query and the retrieved context.
3 Key Benefits of Retrieval-Augmented Generation
Reduction of Response Bias
RAG systems can mitigate the effects of bias inherent in any single dataset or knowledge repository by retrieving information from diverse sources. This helps provide more balanced and objective responses as the system considers a broader range of perspectives and viewpoints. By promoting inclusivity and diversity in the retrieved content, RAG models create fairer and more equitable interactions.
Reduced Risk of Hallucinations
Hallucinations refer to the generation of incorrect or nonsensical information by large language models. RAG systems mitigate this risk by incorporating real-world information retrieved from external knowledge sources.
By retrieving and grounding responses in verified, external information, RAG models are less likely to generate hallucinatory content. This reliance on external context helps ensure that the generated responses are grounded in reality and aligned with factual information, reducing the likelihood of producing inaccurate or misleading output.
Improved Response Quality
The RAG technique can generate relevant, fluent, and coherent responses by combining retrieval and generation techniques, leading to higher-quality outputs than purely generative-based approaches. Clearly, even the best LLM has its limitations – RAG is the technology needed to add a deeper knowledge base.
When to Use RAG vs. Fine-Tuning an AI Model
This chart summarizes the considerations for choosing between RAG and fine-tuning an AI model based on various aspects.
| Criteria | RAG | Fine-Tuning an AI Model |
|---|---|---|
| External knowledge access | Suitable for tasks requiring access to external knowledge sources. | May not require external knowledge access. |
| Knowledge integration | Excels in integrating external knowledge into generated responses, providing more comprehensive and informative outputs. | May struggle to incorporate external knowledge beyond what is encoded in the fine-tuning data, potentially leading to less diverse or contextually relevant responses. |
| Performance trade-off | Offers a trade-off between response latency and information richness, with longer response times potentially resulting in more comprehensive and contextually relevant outputs. | Provides faster response times but may sacrifice some degree of contextual understanding and knowledge integration compared to RAG. |
| Nature of task | Suitable for tasks requiring access to external knowledge sources and contextual understanding, such as question answering, dialogue systems, and content generation. | Ideal for tasks where the model needs to specialize in a specific domain or perform a narrow range of tasks, such as sentiment analysis or named entity recognition. |
| Interpretability | Offers transparent access to retrieved knowledge sources, allowing users to understand the basis for generated responses. | Low interpretability. |
| Latency requirements | Retrieval process may introduce latency, especially when accessing large knowledge sources, but generation itself can be fast once the context is obtained. | Generally faster inference times, as the model is fine-tuned to the specific task and may require less external data retrieval during inference. |
How is Retrieval-Augmented Generation Being Used Today?
Question Answering Systems
RAG models are used in question answering systems to provide more accurate and context-aware responses to user queries. These systems can be deployed in customer support chatbots, virtual AI assistants, and search engines to deliver relevant information to users in natural language.
Search Augmentation
RAG can enhance traditional search engines by providing more contextually relevant results. Instead of simply matching keywords, it retrieves relevant passages from a larger database and generates responses that are more tailored to the user’s query.
Knowledge Engines
RAG can power knowledge engines where users can ask questions in natural language and receive well-informed responses. This is particularly useful in domains with a large amount of structured or unstructured data, such as healthcare, law, finance, or scientific research.
RAG vs. Traditional Approaches
Traditional question and answer approaches rely heavily on keyword matching for information retrieval, which can lead to limitations in accurately understanding user queries and providing relevant results.
In contrast, RAG offers a more advanced and contextually aware approach to information retrieval. Instead of relying solely on keyword matching, RAG leverages a combination of techniques, including natural language understanding and machine learning, to comprehend the semantics and context of user queries. This allows RAG to provide more accurate and relevant results by understanding the intent behind the query rather than just matching keywords.
Bottom Line: Embracing the Potential of RAG
Retrieval-augmented generation holds significant promise for transforming various aspects of natural language processing and text generation tasks. By incorporating the strengths of retrieval-based and generation-based models, RAG can improve the quality, coherence, and relevance of generated text.
Embracing RAG’s potential can lead to more effective and human-like interactions with AI systems, better question answering systems, and enhanced content creation capabilities. This approach can also help address common AI challenges by generating more diverse and informative responses, reducing biases in generated text, and improving the overall performance of language models.
For more information about generative AI providers, read our in-depth guide: Generative AI Companies: Top 20 Leaders